All-Time Spotify Wrapped
Table of Contents
1. Overview
All-Time Spotify Wrapped project aims to create a comprehensive data pipeline that extracts, transforms, and visualizes my complete Spotify listening history using modern data engineering tools and practices. This project recreates Spotify Wrapped that can be viewed at any time of year with richer insights than the official version.
Reference: This project is built upon concepts from spotify-api by calbergs and is developed further into incorporating DuckDB for OLAP database as well as OpenLineage and Marquez for complete column level data lineage.
1-1. Objective
The main goal of this project is to extract all of my song listening history data and continuously extract the Spotify usage activity through Spotify API. I will deep dive into my complete song listening history to analyze top artists, tracks, playlists, and listening patterns.
1-2. Key Features
- Real-time Tracking: Hourly API calls during active hours (0-6, 14-23 UTC)
- Historical Analysis: Integrates 2+ years of extended streaming history (89K+ plays)
- Usage Pattern Discovery: Discover my usage patterns and habits over time
- Data Lineage: Complete automation of column-level lineage tracking with OpenLineage + Marquez
- Cost Efficient: 100% open-source tools, hosted locally
2. Architecture
2-1. Tools & Technologies
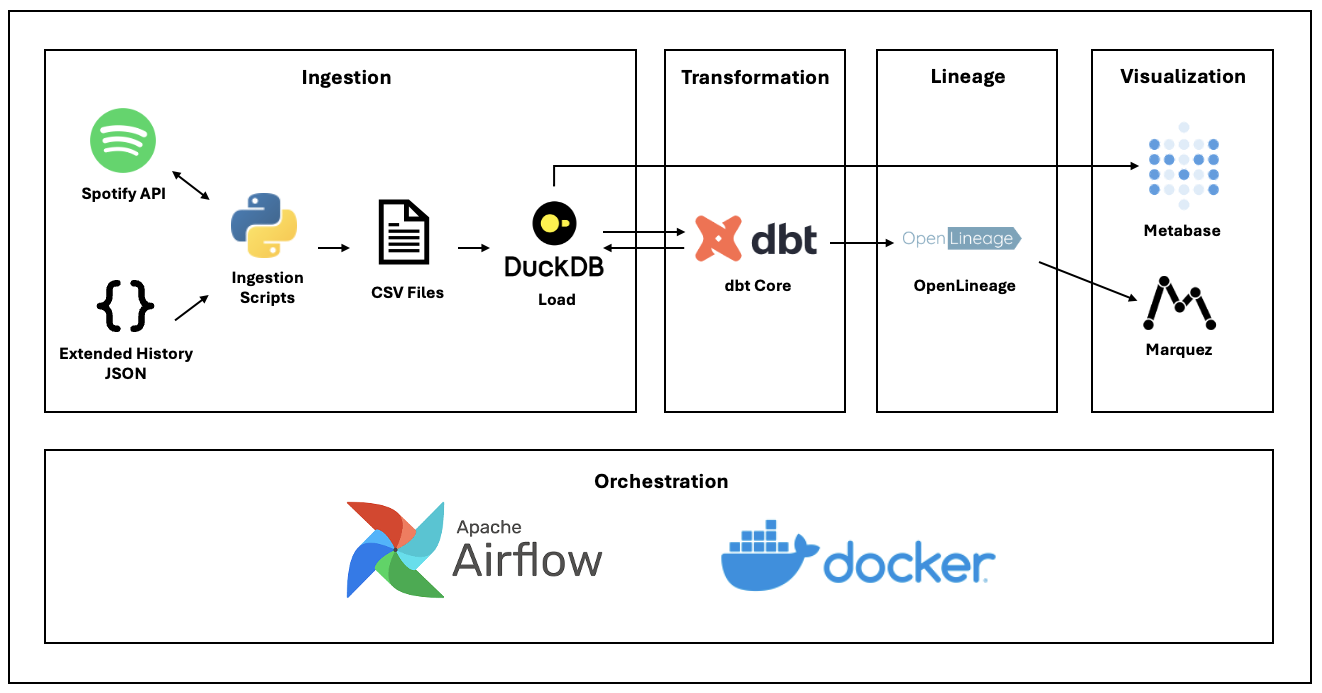
One of the main achievements I wanted out of this project was to learn different tools and technologies by building a complete data pipeline. Since my work environment is primarily in Azure Synapse Analytics, I wanted to use well known open-source tools and technologies such as Apache Airflow, dbt, DuckDB, and Docker to learn what they are capable of and why they are widely used in the industry. Also, as part of data governance, I was interested in implementing an end-to-end column level data lineage, and this project was the perfect opportunity to try implementing it using OpenLineage and Marquez.
2-2. Data Flow
Below is the holistic view of the data pipeline orchestrated by Apache Airflow:
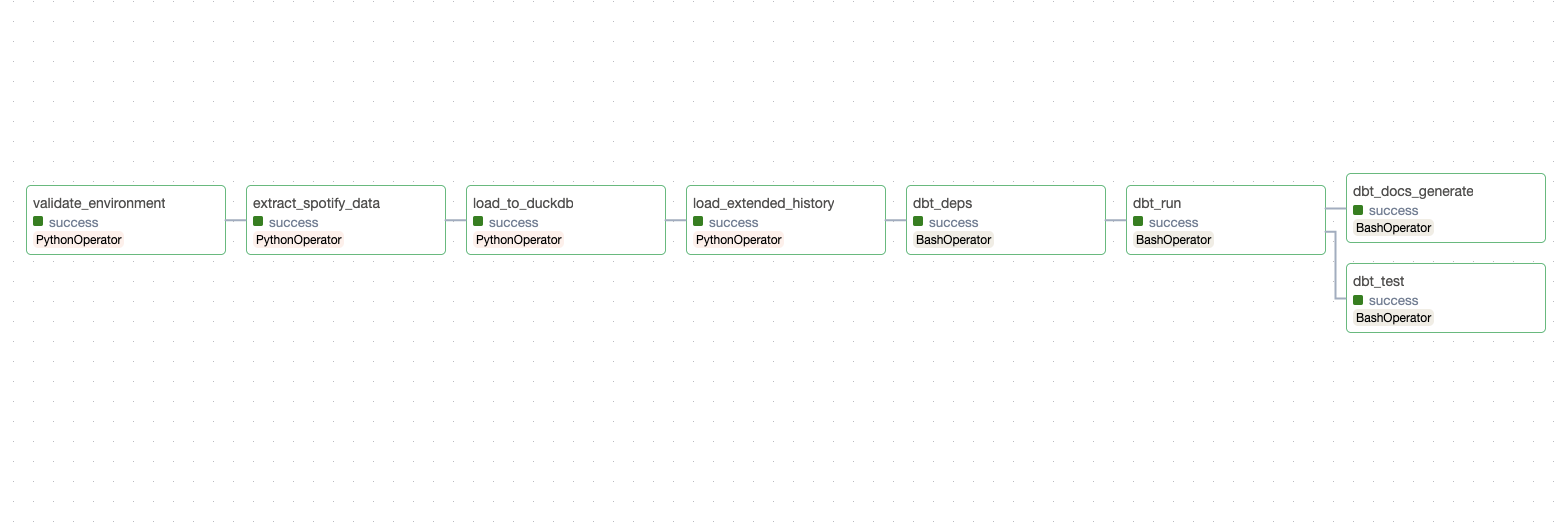
The main components of the data pipeline are Extraction, Loading, Transformation, Lineage Tracking, Quality & Documentation, and Slack Notifications.
1. Extraction
The extraction process has two main parts: API Extraction and Extended History.
- API Extraction is responsible for fetching the recently played tracks and their audio features. The limitation of this API extraction is that it only returns 50 most recent tracks, and this is where the extended history comes into play.
- Extended History is responsible for fetching the historical streaming data from Spotify. Unlike the API extraction, this I need to manually request the extended history data from Spotify. Once I receive the data in JSON format, I need to parse the data and store it as a CSV file.
2. Loading
After ingesting the data from the extraction process, they are loaded into DuckDB for further analysis.
One issue I'm facing right now is that with multiple connections to the same DuckDB database, the database file is getting locked and I have to restart the docker container every time to unlock the database. My highest priority right now is to resolve this issue. The major approach I'm trying is to change the database configuration in Metabase to establish a read-only connection, but this doesn't seems to resolve the issue. Other approaches I'm considering is to set up a retry mechanism to set an exponential backoff delay for the connection to the database, but so far, the only temporary resolution is to restart the docker container.
3. Transformation (dbt)
dbt is used to transform the loaded data into a star schema for analysis. What I focused here was to have a proper dimensional modeling implemented and have a medallion structure. The tables are organized into three different layers: Staging Layer, Marts Layer, and Analytics Layer. Tables in staging layer is essentially silver tables where the raw data is loaded and cleaned up. The gold tables are in the mart layer, having fact tables and dimension tables from the silver tables. The analytics layer is the layer where different tables for analytics are created.
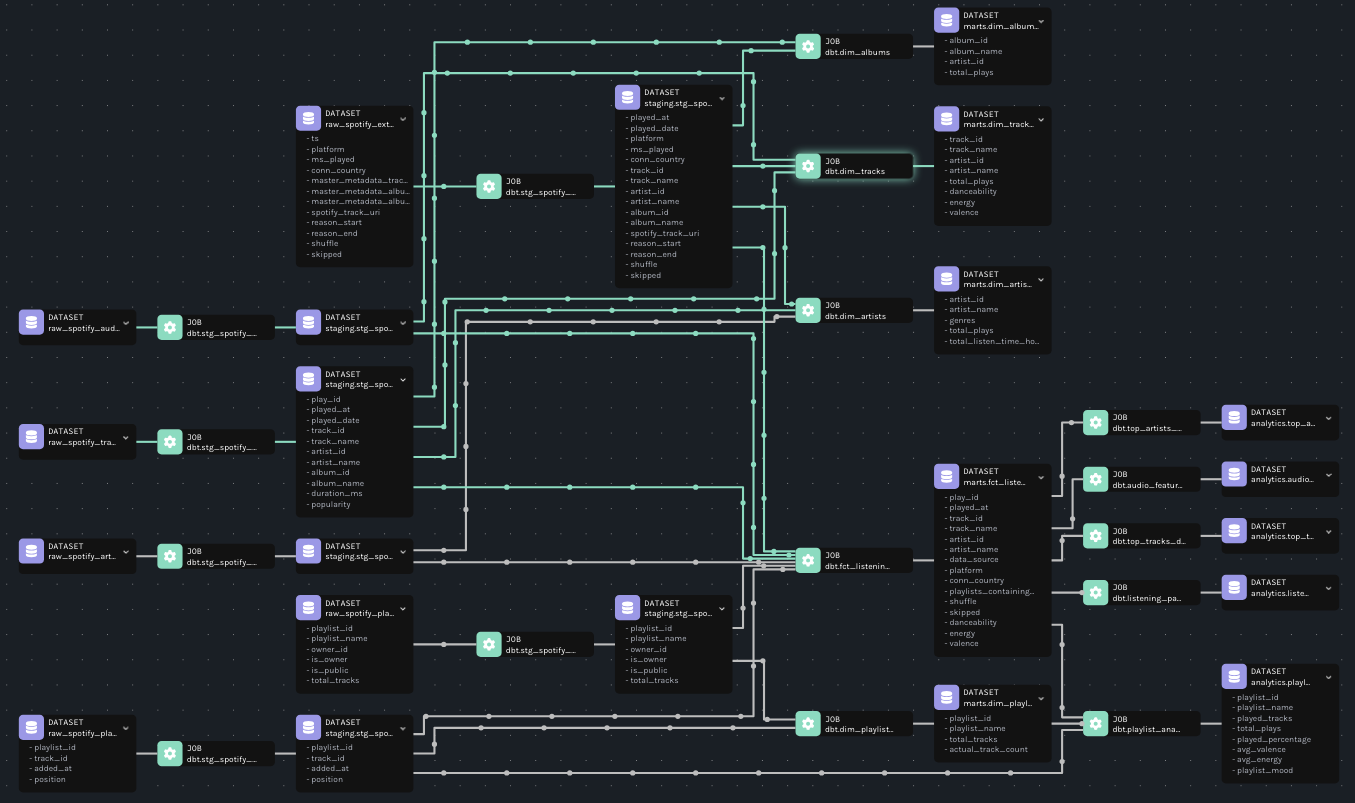
4. Lineage Tracking
I was able to automate end-to-end column level lineage tracking for all dbt models using OpenLineage. One challenge I faced here was integrating OpenLineage with dbt. The official documentation suggests that running dbt-ol run instead of dbt run automatically emits column level lineage. However, running the command gave me an error saying that dbt-ol does not support duckdb, so as a woraround, I had to make a separate script in python to manually emit the lineage events. Later, I found out that I wasn't downloading the correct version of the package openlineage-dbt, so configuring the exact version of the package resolved the issue, and I was able to automate column level lineage of all 16 dbt models.
5. Quality & Documentation
For the dbt models, I wanted to test out the dbt test and documentation features, so I added some light tests and documentation to the models for the data governance purposes. For the next step, I want to implement more comprehensive data quality checks that cross reference different columns and tables to ensure the data is accurate and consistent. I want to also be able to create a data quality dashboard if I can get the data quality testing data from dbt.
6. Slack Notifications

To ensure that I am notified for any pipeline failures or retries, I integrated Slack into the pipeline to send notifications to my Slack workspace. The message tells me the task that failed, the error message, and the retry count. I thought this was a good way to ensure even when I am out of home to check on the pipeline, I can still be notified and take action accordingly.
3. Dashboard & Insights
Metabase Dashboard
Below are visualizations from the Metabase dashboard showcasing comprehensive Spotify listening analytics:
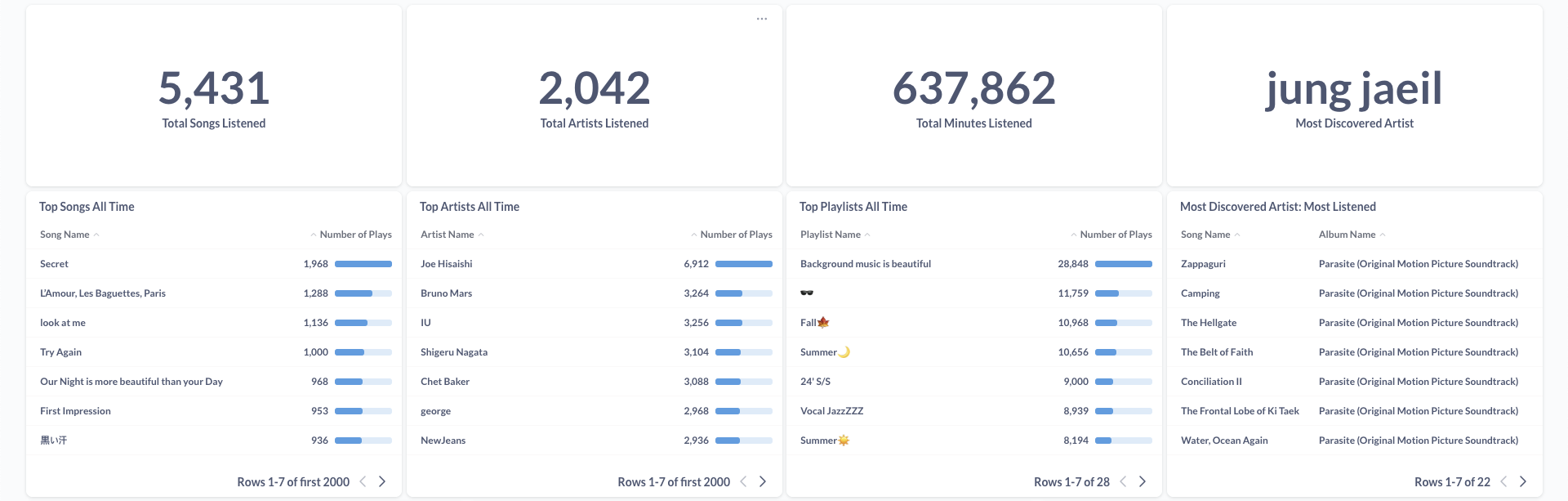
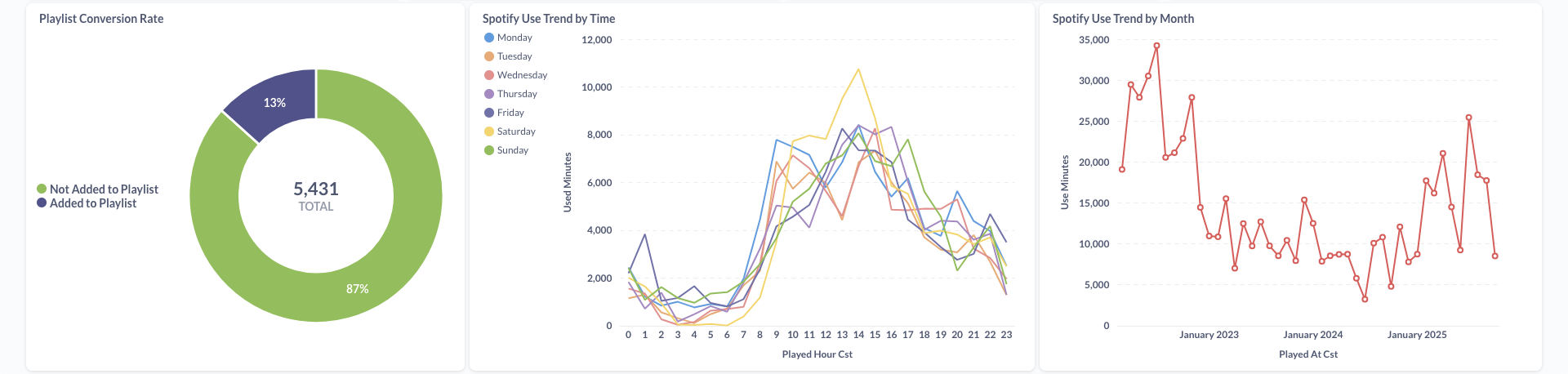
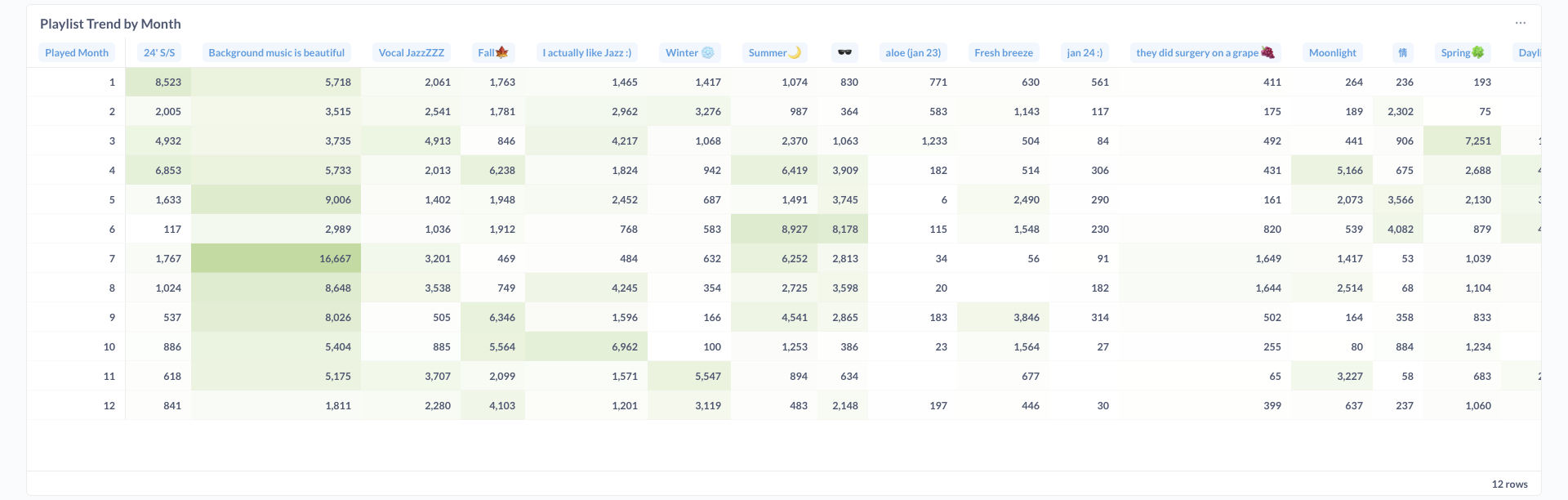
The current official latest version of Metabse has a limitation where it doesn't support DuckDB integration. Due to this issue, I originally had to sync the data to PostgresSQL and then connect Metabase to PostgresSQL directly, which created unnecessary work and time. Fortunately, Metabase had a version with a DuckDB Driver that officially supports DuckDB integration, so I was able to directly connect Metabase to DuckDB and reduce the time and amount of work the data pipeline had to go through.
4. Things I Learned
Throughout the course of this project, I learned a lot about the foundations of data engineering and data pipeline orchestration. This was a great opportunity to learn about modern data engineering technique, including how to use Apache Airflow to orchestrate the data pipeline and how to use dbt to transform the data. I read a lot of articles about how good DuckDB is, so having a chance to have the experience of loading the data in DuckDB gave me a better understanding of its capabilities. One thing that I'm really satisfied about this project is that I got to use OpenLineage to track the column level lineage of the dataand visualize it through Marquez. I have been wanting to learn how to incorporate OpenLineage specifically to retrieve column level lineage from my work environment, so this project was a great starting point on that journey.
5. Future Improvements
I think there is a lot of room for improvement for this project. As of now, I'm thinking about focusing on the following areas for my next steps:
- Implementing more comprehensive data quality checks that cross reference different columns and tables to ensure the data is accurate and consistent
- Creating a data quality dashboard if I can get the data quality testing data from dbt
- Connecting the data to this website to create more unique and interactive visualizations
- Create more comprehensive visualizations out of the data
- Deep dive into the data analysis/data science after switching to Spotify Premium (More advanced data from the API with a Spotify Premium plan)
Along with the above improvements, I'm planning on having a major update on the project to make it be multi-user compatible. Having multiple users be able to use this project to see their own music listening history and analytics would be a great addition and would make the project significantly more useful.
Acknowledgments
- calbergs for the basic guideline of the project
- Spotify for providing comprehensive Web API
- Open-source communities behind Airflow, dbt, DuckDB, OpenLineage, and Marquez
- Inspired by Spotify Wrapped
License
This is a personal project for educational and analytical purposes. Spotify API usage complies with Spotify's Developer Terms.